
I’m here in sunny San Jose attending GTC14, the annual GPU-fest sponsored by NVIDIA. This is my favorite event of the year. Why? Because of the way it’s organized. At GTC, real-world researchers, analysts, and other customers present the vast majority of sessions. They talk about their projects, the challenges they’ve dealt with, and their findings. Of course, they also talk about how GPUs helped them out along the way, but that’s what you get at a conference focusing on GPU technology.
Case in point was my first session on Monday. Titled “Speeding Up GraphLab Using CUDA”, it featured Vishal Vaidyanathan from Royal Caliber discussing the wide world of graph problems and the massive computational challenge these problems present.
Graph problems are everywhere. One of the most familiar is the typical routing problem: for example, figuring out the shortest route between a set of cities. In graph problem lingo, the cities would be called vertices, and the line between two of them an edge.
The more vertices you have, the more computationally complex the graph problem. They’re also very difficult to parallelize. Partitioning a graph problem onto different systems, for example, doesn’t help very much.
Using our city example, you’d place some cities on System A and the others on System B. However, these two groups are intimately connected. Testing for an optimal route would require many hops between “A” and “B”, meaning that the processors spend much of their time coordinating their tests instead of computing possible optimal routes.
GraphLab was a huge step forward in aiding the parallelization of graph problems. Royal Caliber, with the help of others, have added a GPU API onto GraphLab and are presenting it as VertexAPI2. And the results are, well, pretty GPU-riffic.
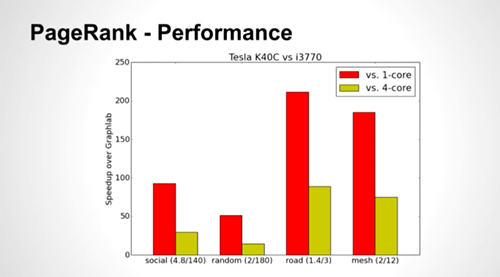
The Y axis is the speed-up attained by VertexAPI2 on Tesla K40C vs. GraphLab running on a single-core, then quad-core i3770 Xeon processor. Not surprisingly, the GPUs outperform the single-core CPU by 50-220x and the quad-core by 15-100x.
In the session, Vishal discusses the three overriding goals for VertexAPI2. The first is making it easy to code, and the second is hiding all of the GPU-specific details; in other words, making Vertex as easy to use as GraphLab running on native x86 cores. The third goal is to have it perform like a scorched weasel, i.e., fast.
Vishal also goes into the details about the API, how it works, how to use it, and compares their approach to other graph problem algorithms such as BFS (Best First Solution). NVIDIA already has this session online, so you can watch it from your desk right now. Well, you have to click here first. Then you can watch it.